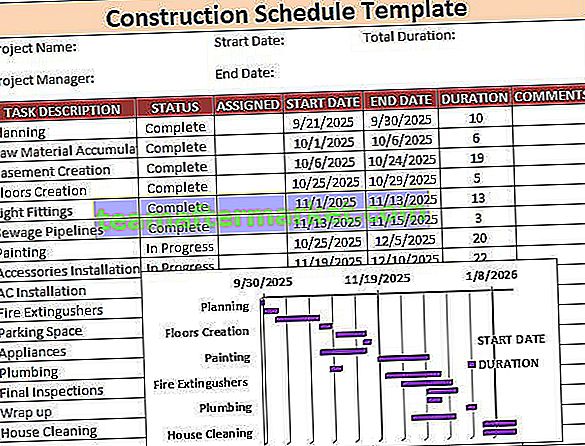
Formel för beräkning av provtagningsfel
Provtagningsfelformel hänvisar till formeln som används för att beräkna statistiska fel som uppstår i den situation där personen som utför testet inte väljer prov som representerar hela befolkningen som övervägs och enligt formeln beräknas provtagningsfel genom att dela standardavvikelse för populationen med kvadratroten av storleken på provet och sedan multiplicera resultatet med Z-poängvärdet som är baserat på konfidensintervallet.
Provtagning Fel = Z x (σ / √ n)
Var,
- Z är Z-poängvärdet baserat på konfidensintervallet
- σ är populationsstandardavvikelsen
- n är provets storlek
Steg för steg-beräkning av provtagningsfel
- Steg 1 : Samlade alla uppsättningar data som kallas befolkningen. Beräkna populationens medelvärde och befolkningsstandardavvikelse.
- Steg 2 : Nu måste man bestämma storleken på provet, och vidare måste provstorleken vara mindre än populationen och den ska inte vara större.
- Steg 3 : Bestäm konfidensnivån och följaktligen kan man bestämma värdet på Z-poäng från dess tabell.
- Steg 4 : Multiplicera nu Z-poäng med populationsstandardavvikelsen och dela samma med kvadratroten av provstorleken för att nå en felmarginal eller felstorlek.
Exempel
Du kan ladda ner denna samplingsfelformel Excel-mall här - Samplingsfelformel Excel-mallExempel nr 1
Antag att befolkningsstandardavvikelsen är 0,30 och storleken på urvalet är 100. Vad kommer provtagningsfelet vid 95% konfidensnivå?
Lösning
Här får vi populationsstandardavvikelsen samt storleken på provet, därför kan vi använda formeln nedan för att beräkna densamma.
Använd följande data för beräkningen.

Därför är beräkningen av samplingsfelet som följer,

Provtagningsfel kommer att vara -

Exempel 2
Gautam går för närvarande på en bokföringskurs och han har godkänt sin antagningsprov. Han har nu registrerat sig för en mellannivå och kommer också att gå in i en senior revisor som praktikant. Han kommer att arbeta i en granskning av tillverkningsföretagen.
Ett av de företag han besökte för första gången ombads att kontrollera om räkningarna för alla inköpsposter var rimligt tillgängliga. Provstorleken han valde var 50 och befolkningsstandardavvikelsen för densamma var 0,50.
Baserat på tillgänglig information måste du beräkna samplingsfel vid 95% och 99% konfidensintervall.
Lösning
Här får vi populationsstandardavvikelsen samt storleken på provet, därför kan vi använda formeln nedan för att beräkna densamma.
Z-poäng för 95% konfidensnivå blir 1,96 (tillgänglig från Z-poängtabellen)
Använd följande data för beräkningen.

Därför är beräkningen som följer,

Provtagningsfel kommer att vara -

Z-poäng för 95% konfidensnivå blir 2,58 (tillgänglig från Z-poängtabellen)
Använd följande data för beräkningen.

Därför är beräkningen som följer,

Provtagningsfel kommer att vara -

När konfidensnivån ökar ökar också samplingsfelet.
Exempel # 3
I en skola organiserades den biometriska sessionen för att kontrollera elevernas hälsa. Sessionen inleddes med elever i klass X-standard. Totalt finns det 30 studenter i B-avdelningen. Bland dem valdes 12 studenter slumpmässigt för att göra detaljkontroll och vila var, ett enda grundläggande test gjordes. Rapporten drog slutsatsen att elevernas genomsnittliga höjd i B-avdelningen är 154.

Lösning
Befolkningsstandardavvikelsen var 9,39. Baserat på ovanstående information måste du beräkna samplingsfelet för 90% och 95% konfidensintervall.
Här får vi populationens standardavvikelse samt storleken på provet, därför kan vi använda formeln nedan för att beräkna densamma.
Z-poäng för 95% konfidensnivå blir 1,96 (tillgänglig från Z-poängtabellen)
Använd följande data för beräkningen.

Därför är beräkningen av samplingsfelet som följer,

Provtagningsfel kommer att vara -

Z-poäng för 90% konfidensnivå blir 1.645 (tillgänglig från Z-poängtabellen)
Använd följande data för beräkningen.

Därför är beräkningen som följer,

Provtagningsfel kommer att vara -

När konfidensnivån minskar minskar också samplingsfelet.
Relevans och användningsområden
Detta är mycket viktigt för att förstå detta koncept eftersom detta ska skildra hur mycket man kan förvänta sig att undersökningsresultaten faktiskt skulle skildra den faktiska synen på befolkningen totalt sett. Man måste ha en sak i åtanke att en undersökning utförs med en mindre befolkning som kallas urvalsstorleken (även annars känd som respondenterna i undersökningen) för att representera en större befolkning.
Det kan ses som ett sätt att beräkna undersökningens effektivitet. När provtagningsmarginalen är högre ska det representera att undersökningens konsekvenser kan avvika från den faktiska totala befolkningsrepresentationen. På baksidan är ett samplingsfel eller felmarginal mindre än vad som ska indikera att konsekvenserna nu är närmare den totala representationen av befolkningen totalt och som ska bygga en högre grad av förtroende för den undersökning som är under överblick.